Key points
- To use machine learning we require 4 basic components: Data, a model, a cost function (learning objective) and an optimization method (learning algorithm)
- Learning algorithms learn parameters to solve an equation. The prediction given by machine learning is based on the solution of that equation.
- Machine learning scientist provide the ‘backbone’ of the equation, but the learning algorithm learns ‘the details’ based on the given data.
Machine learning is a technology that is gaining more relevance every day. From cars that will be able to drive by themselves to precision medicine that will help physicians to determine the best treatment for a given patient, machine learning is finding its way into almost every industry.
Natural questions are then: How it works? What do we mean when we say that a computer “learns”? When can we expect this technology to be useful? I will try to answer these questions in this post.
What is machine learning?
Kevin Murphy, author of the book Machine Learning: A probabilistic perspective, defines it as ” a set of methods that can automatically detect patterns in data, and then use those patterns to predict future data, or to make decisions under uncertainty”.
This means that we can use machine learning when we are interested in making predictions. For example, we might want to predict the price of house given its characteristics, or to diagnose a mental disease (like schizophrenia, or autism) given images of the brain. This task is slightly different than traditional statistical analysis, which aim to gain deeper knowledge about a phenomenon. I describe some of these differences in this other post.
Different types of machine learning
Roughly speaking, machine learning can be classified in three types: supervised learning, unsupervised learning, and reinforcement learning. I will limit this post to the case of supervised learning.
Supervised learning
This is the most common approach. The goal is to build a tool that will allow us to make predictions on new data. It requires ‘labeled data’.
As an example, assume that you want to predict the price of a house (aka the target) given three characteristics (aka the features): its area, number of rooms, and neighbourhood. Then you need to construct a dataset that contains records of several houses. These records must contain all: the area, number of rooms, neighbourhood and price of every house.
The learning algorithm will use then this data to predict the price of previously unseen houses, given the features. Depending on the nature of the target, we divide supervised learning in two sub-types:
- Classification: When the target is a class or group. For example, when we want to classify a person as healthy or with a disease.
- Regression: When the target is a number. For example, the price of a house.
The next figure illustrates the basic framework of supervised learning:
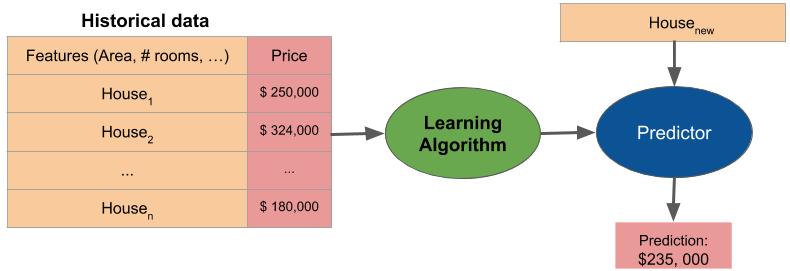
How machine learning works?
There are many machine learning algorithms, such as support vector machines (SVM), logistic regression, linear regression, neural networks, etc. Roughly speaking,we can reduce most of the algorithms as solving an equation. This equation relates the target to the features. For example, when we want to predict the price of a house:
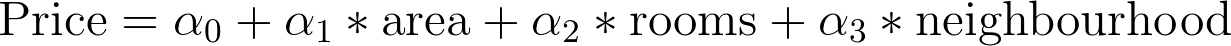
The learning task is then to find the numbers α, that makes ‘the best’ prediction. Different algorithms might have slightly different equations, but in general they all work in this way.
Usually, a machine learning algorithm will start with random guesses of the values of α. Then, as it analyzes the data, it will modify the α’s to make ‘better predictions’. Of course, we need to define what we mean by ‘better’.
Besides the previous equation, known as the model, we need to define a cost function. This cost function guides the search of the parameters α. In general, the algorithm will try to find the values α that make the cost function as low as possible. In our example of house price prediction, we can choose a cost function the penalizes large discrepancies between our predicted price and the real price of the house. One possible cost function is:
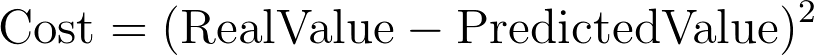
What does machine learning learn?
The learning algorithms learn in a very different way that we do. When we say that the computer learns, we mean that it finds the best parameters it can. By best, we mean those parameters that make the cost function as low as possible.
In general, there are four things that we need to provide if we want to use machine learning:
- Data, which will be used to determine the best parameters.
- A model, which is an equation like the one we showed previously.
- A cost function, which will tell the algorithm how good the current parameters are.
- An optimization method, which is a method to update the parameters so the value of the cost function goes down.
For example, assume that the real price of a house is $100,000. We have two set of parameters. The first one predicts the price as $200,000; while the second one predicts the price as $120,000. Then the algorithm will learn that the second set is better because the penalty is lower in this case. The cost function defines this penalty.
We can explain in this way even the most advanced algorithms that can analyze images, or can talk to people. Of course, the equations are not as simple as the ones presented in this post, but still, they are solving equations.
Fortunately, there are many tools out there that make most of the work for us. Libraries like scikit-learn, TensorFlow, etc already provide the models, cost functions and optimization methods, so we just need to feed them data. Unfortunately, most of the time the default models, cost function and optimization methods are not enough to solve our task. We need to modify them to achieve a better performance.
A final word
As you can see, machine learning is far from being magic. In essence, it is mathematics, statistics, and optimization. The computer learns a set of parameters that solve those equations to minimize an objective that we have in mind, like the number of mistakes made, or large deviations from the things we want to predict.
This might sound simple, but it is not. A lot of effort is required to build this models and find effective ways of optimize them. Despite being just equations, very smart people spends large amount of resources looking for the right equations to solve. Also, even when the computer only learns the parameters, this can be a very powerful tool. Current models out there have millions of parameters, which allow them to make very impressive things like driving cars, talking to people, recognizing images, etc.
Also, many of the parameters learned by the computer can define new equations themselves, so we don’t have to explicitly define all the equations that the computer have to solve. In more complex models, the computer can learn which equations to solve by itself. Of course, we would need to provide some of the equations that will guide the computer to learn the new equations. However, all of this learning has the objective of minimize the value of the cost function, which we always define. Also, it is restricted to solve the model that we provide. Machine learning do not create sentient programs. So don’t worry, no chance of developing skynet with these models…
This article originally appeared in Roberto Vega